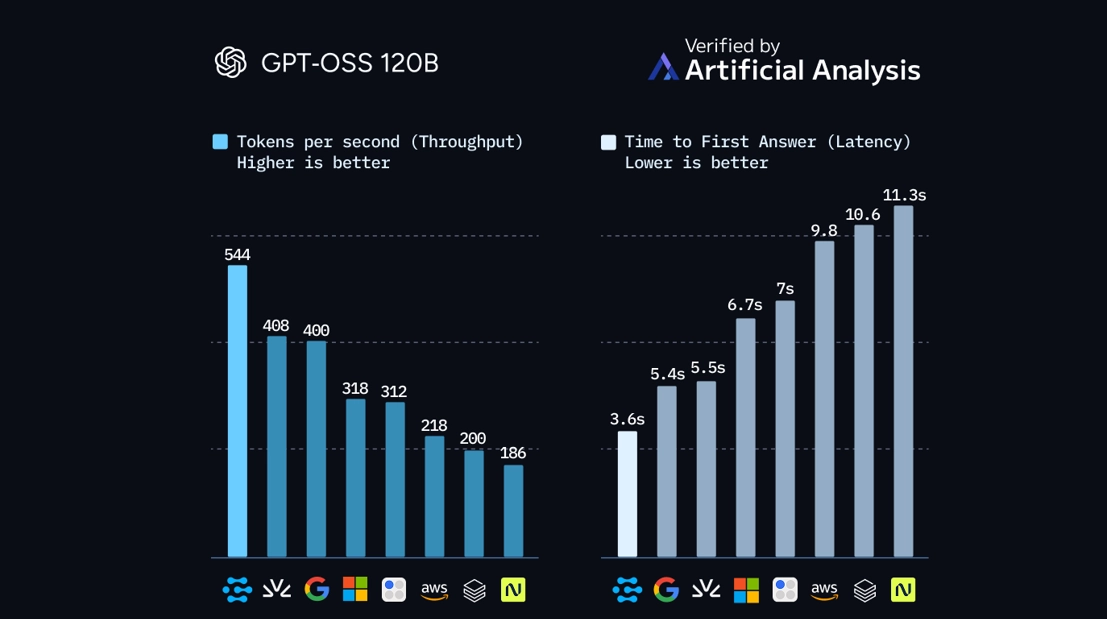
Clarifai’s latest benchmark on OpenAI’s GPT-OSS-120B model points to a quiet but important shift in AI infrastructure. Using its new Clarifai Reasoning Engine for agentic AI inference, the company recorded 544 tokens per second at a blended price of $0.16 per million tokens, as measured by independent firm Artificial Analysis. In the same benchmark, Clarifai outperformed all other providers tested, including vendors using custom inference silicon such as SambaNova and Groq.
The result doesn’t settle the GPU-versus-ASIC debate, but it does show that a well-optimized GPU stack can compete at the top end of large-model inference without custom hardware. For teams running agentic and reasoning-heavy workloads, it is a signal that software and serving architecture may now matter as much as chip choice.