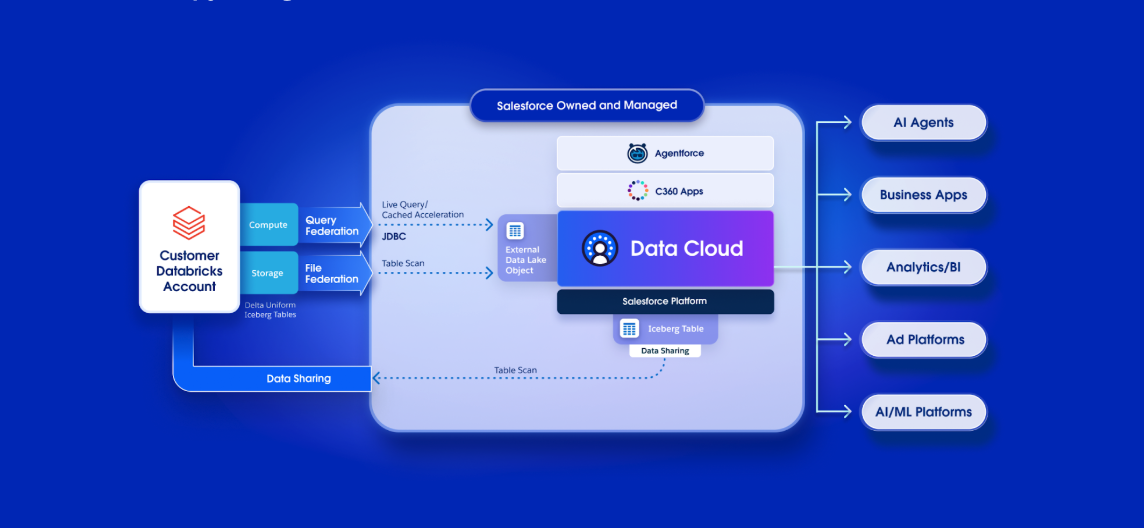
Salesforce and Databricks are tearing down the walls between their data platforms. The two enterprise giants have announced the General Availability of a bi-directional, Zero Copy integration, signaling a major shift away from the slow, costly data pipelines that have plagued businesses for decades. The new integration allows Salesforce Data Cloud and the Databricks Data Intelligence Platform to access each other's data in near real-time, without making copies.
For years, the holy grail of a 360-degree customer view has been a mirage, shimmering behind a desert of brittle ETL processes and stale data. Companies keep their transactional and log data in powerful lakehouses like Databricks, while their customer relationship data lives in CRMs like Salesforce. Getting them to talk to each other meant building complex, expensive pipelines to constantly copy data back and forth. By the time the data arrived, it was already out of date.