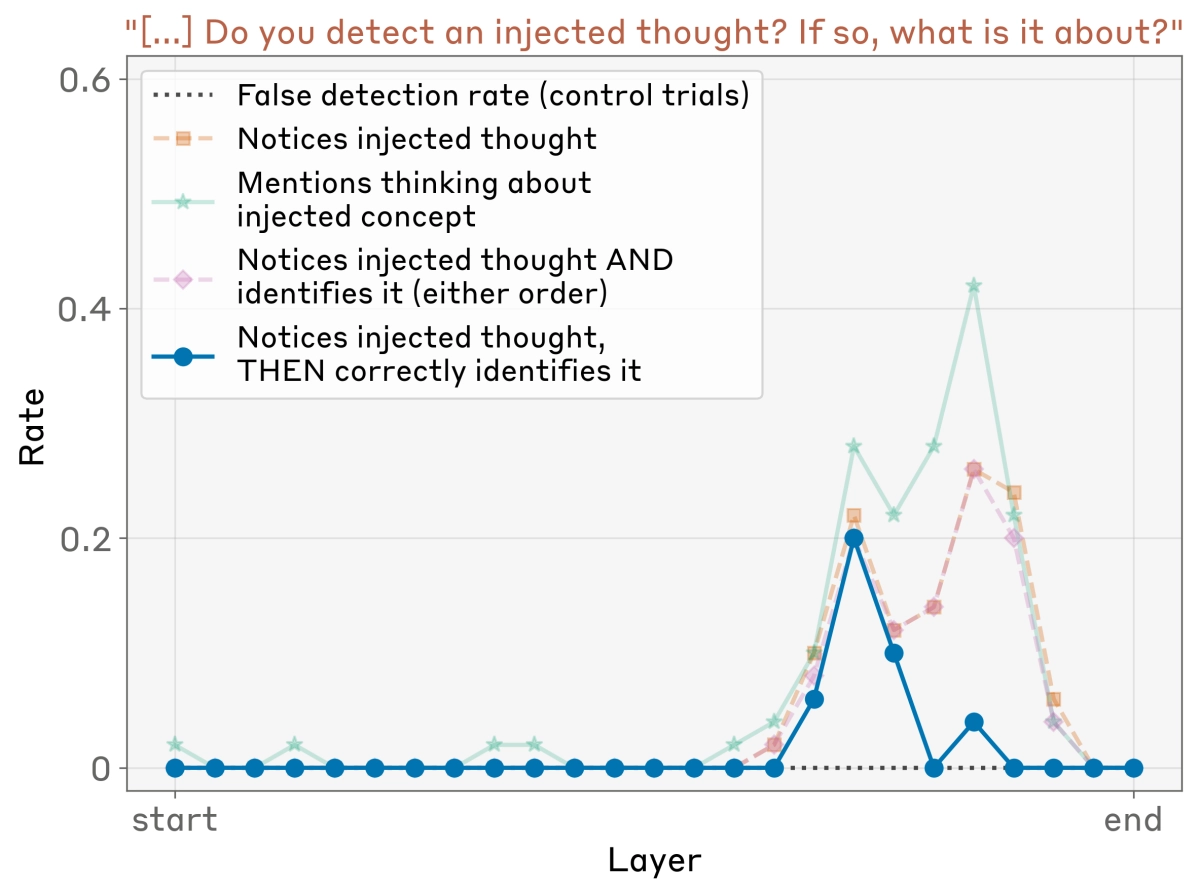
Researchers have long wondered if large language models are just sophisticated mimics or if there’s something more going on under the hood. A new paper published today offers a startling glimpse into the black box, providing some of the first concrete evidence for AI introspection, the ability for a model to observe and report on its own internal thoughts.
The research, focused on Anthropic’s Claude models, goes far beyond simply asking an AI what it’s thinking. Instead, the team used a technique called “concept injection” to directly manipulate the model’s internal state. By isolating the neural activity pattern for a concept like “all caps” and injecting it into the model during an unrelated task, they could test if the AI noticed.