
The prevailing narrative in AI infrastructure often centers on NVIDIA's dominance, yet an intriguing counter-current is emerging, championed by companies like Zyphra. In a recent discussion on the Latent Space podcast, Alessio Fanelli spoke with Quentin Anthony, Head of Model Training at Zyphra and advisor at EleutherAI, delving into Zyphra's bold strategic pivot to AMD hardware and its implications for the future of AI model development and deployment. Anthony’s insights reveal a philosophy of deep technical engagement, challenging industry complacency and demonstrating a path to competitive advantage.
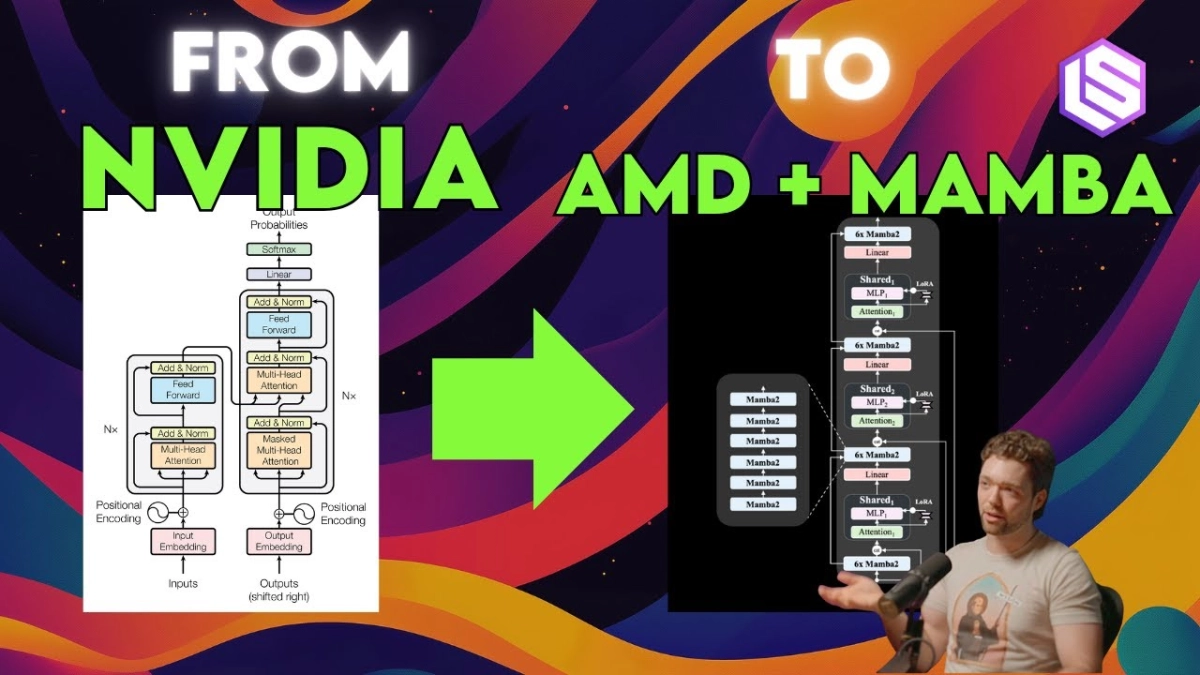
Zyphra, a full-stack model company, handles everything from data curation to model deployment, with a particular focus on edge AI. A significant strategic decision for the startup was to migrate its entire training cluster to AMD. "We recently moved all of our training cluster over to AMD," Anthony stated, highlighting a belief that AMD offers "really compelling training clusters" that significantly reduce their operational costs. This move was not without its foundational challenges, rooted in Anthony’s prior experience working on the Frontier supercomputer at Oak Ridge National Lab, which is entirely based on AMD MI250X GPUs. This necessity forced him to port complex operations like Flash Attention to AMD hardware, an arduous but ultimately revealing process.
Anthony’s direct experience underscores a critical insight: while NVIDIA has historically held a software advantage, AMD's latest MI300X GPUs offer compelling hardware metrics. He notes that for memory-bound operations or those involving parallelism, AMD's MI300X, with its 192GB VRAM and superior memory bandwidth, can outperform NVIDIA H100s. "The less time you spend in like dense compute... and the more time you spend in parallelism or moving to and from HBM, AMD MI300X actually has quite a bit better hardware metrics on those," Anthony explained. This suggests that for specific workloads, especially those not reliant on FP8 dense computations, AMD presents a potent and cost-effective alternative.
The journey to harness AMD’s potential, however, demanded an unconventional approach to kernel development. Anthony openly critiques the industry's tendency towards high-level frameworks like Triton, opting instead for direct coding in ROCm or even GPU assembly when necessary. His philosophy is distinctly "bottom-up": understanding the intrinsic properties of the hardware first, then designing algorithms to fully exploit those capabilities. This stands in contrast to a "top-down" approach that might abstract away hardware specifics, potentially leaving performance on the table. He posits that much of the perceived "software problem" with AMD was partly historical hardware limitations and a lack of dedicated, low-level optimization efforts. "If you evaluate everything evenly, you find these sort of diamonds in the rough," he remarked, suggesting that many developers simply haven't pushed the envelope with AMD's ecosystem, creating an opportunity for those willing to do the deep work.
Zyphra's innovation extends to its model architectures. The company has been at the forefront of state-space model hybrids, like their Zamba 2, which combines transformers and Mamba2 blocks. Anthony proudly notes that Zamba 2, a 7B parameter model, can match the performance of Llama 3 8B. These models are optimized for edge deployment, scaling from 1.2B models for phones to 7B for desktops, demonstrating a commitment to efficient, on-device AI. This strategy of developing a spectrum of models tailored to diverse hardware constraints, from resource-limited edge devices to more powerful local clusters, is key to their vision of ubiquitous AI.
Related Reading
- Amazon's AI Investments Drive AWS Re-acceleration and Retail Innovation
- AI Capex Cycle Shifts to Scrutiny, Not Stagnation
- Wall Street's AI Reckoning: Monetization Separates Hyperscaler Winners from Losers
Anthony also offered candid thoughts on AI's role in developer productivity and the challenges of low-level code generation. While acknowledging AI's utility for high-level tasks like code fusion or generating boilerplate, he remains skeptical about its current ability to produce optimized, low-level GPU kernels. He finds that models often generate "dead basic" or outright incorrect low-level code, which is then difficult to debug due to the inherent parallelism and complexity of GPU operations. He prefers direct API access over tools like Cursor, prioritizing complete control over context and avoiding the "slot machine effect" of endlessly prompting models. The challenge of creating robust kernel datasets and reliable evaluation metrics further complicates AI's role in this domain.
The path Zyphra is forging with AMD is a testament to the power of deep technical expertise and strategic hardware choices in a landscape dominated by a single player. By embracing the nuances of AMD's architecture and investing in foundational kernel development, Zyphra is not only reducing costs but also achieving performance breakthroughs that could reshape the competitive dynamics of AI model training and deployment.


