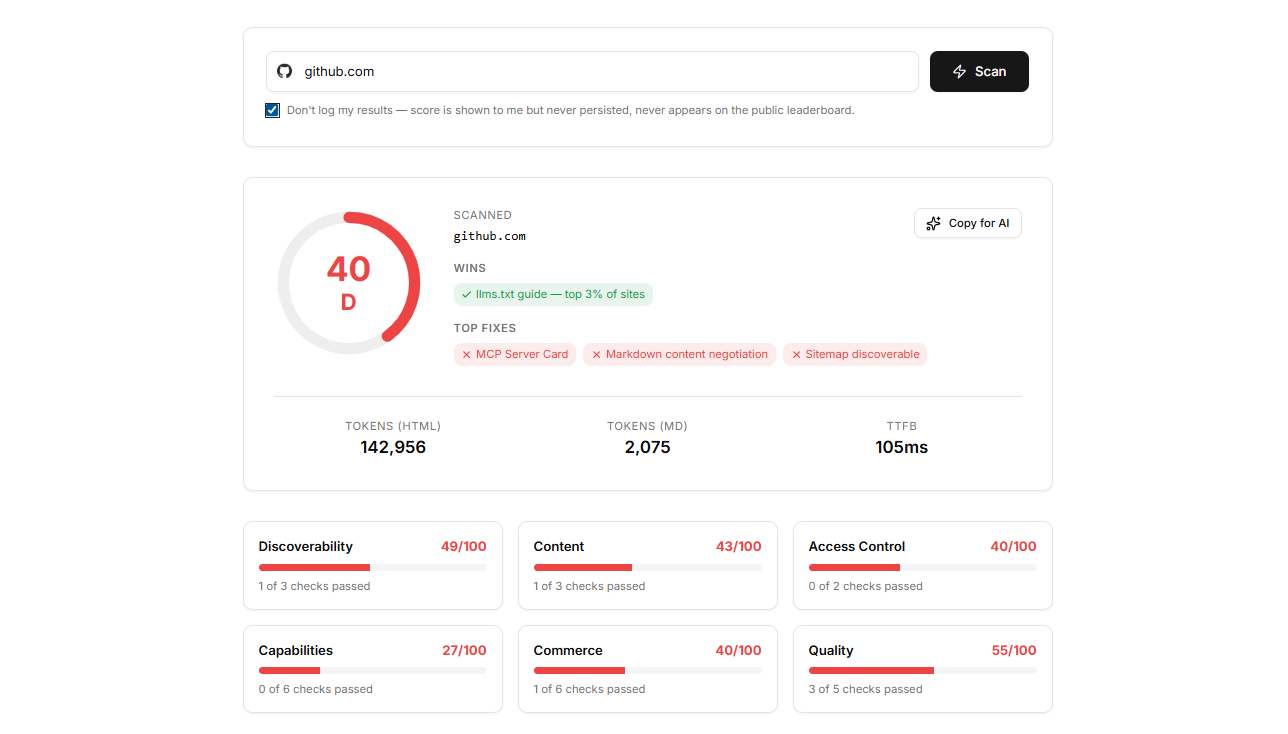
April 20, 2026 was the day we shipped the first version of Agent Readiness, a free, public scanner that scores any URL against 50+ signals AI agents use to actually understand a website. Six dimensions: Discoverability, Content, Access, Capabilities, Commerce, Quality. Letter grade A+ through F. Free, no signup, MCP-callable from Claude Desktop or Cursor.
We built it because we run the largest AI startup directory on the web and watched the same gap show up across thousands of company sites: agents could find a homepage but couldn't do anything with it. The HTML was scaffold-heavy and JavaScript-gated. There was no llms.txt, no machine-readable pricing, no schema.org markup beyond the bare minimum, no MCP server card, no graceful fallback when an agent set Accept: text/markdown. Founders were spending six figures on SEO without realizing the next search interface, Perplexity, ChatGPT, Claude, was going to score them on entirely different rails.