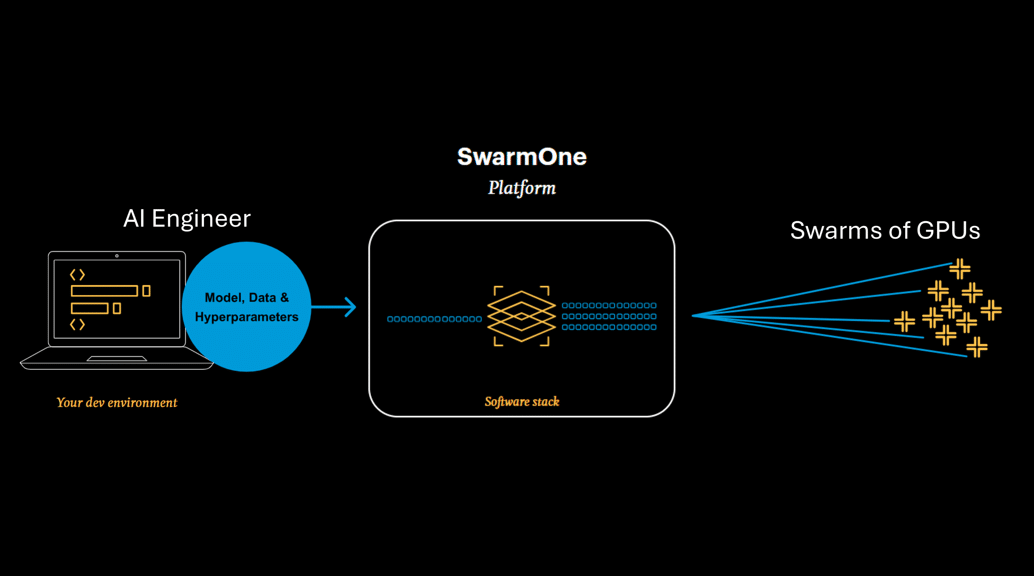
Instance-based cloud computing is complex, expensive and slow, the entire data science community knows this. What you might not know is that two out of three AI models currently fail to make it into production as a result of these issues. There are huge engineering efforts, time and friction associated with it because of issues surrounding GPU size and quality.
In addition to this, numerous personnel are required to complete a training task. These must be extremely skilled people, such experts in MLOps, DevOps, SecOps and FinOps, who are notoriously difficult to find and expensive to recruit.