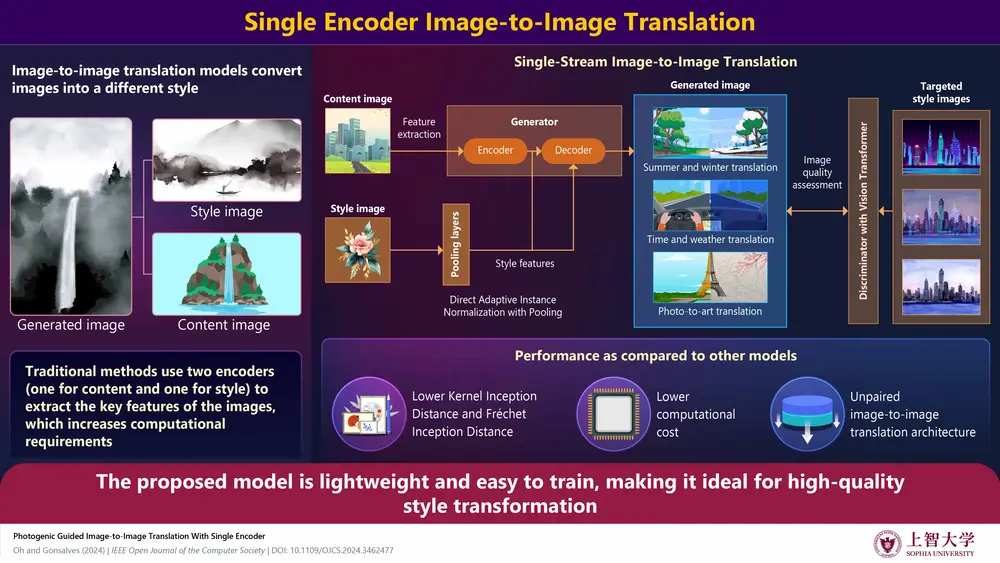
Researchers from Sophia University have introduced the Single-Stream Image-to-Image Translation (SSIT) model, a groundbreaking advancement in efficient image translation. Traditional models powered by Generative Adversarial Networks (GANs) require high computational power, limiting their use to advanced hardware. The SSIT model addresses this challenge by significantly reducing computational demands, making it viable for devices such as smartphones. This advancement has wide-ranging applications in fields like digital art, design, and autonomous technology.
Unlike traditional models that use two encoders to process content and style images separately, the SSIT model employs a single encoder to extract spatial features such as shapes and layouts from content images. It utilizes Direct Adaptive Instance Normalization with Pooling (DAdaINP) to capture style details like colors and textures more efficiently. By combining these features, the model generates high-quality image transformations with lower computational costs, preserving both content and style integrity.