Perplexity, the company behind the popular AI-native answer engine, is opening up its core infrastructure to the public today with the launch of the Perplexity Search API. This isn't just another way to get a list of blue links; it's a direct challenge to legacy search providers and a foundational play to become the information backbone for a future dominated by AI agents.
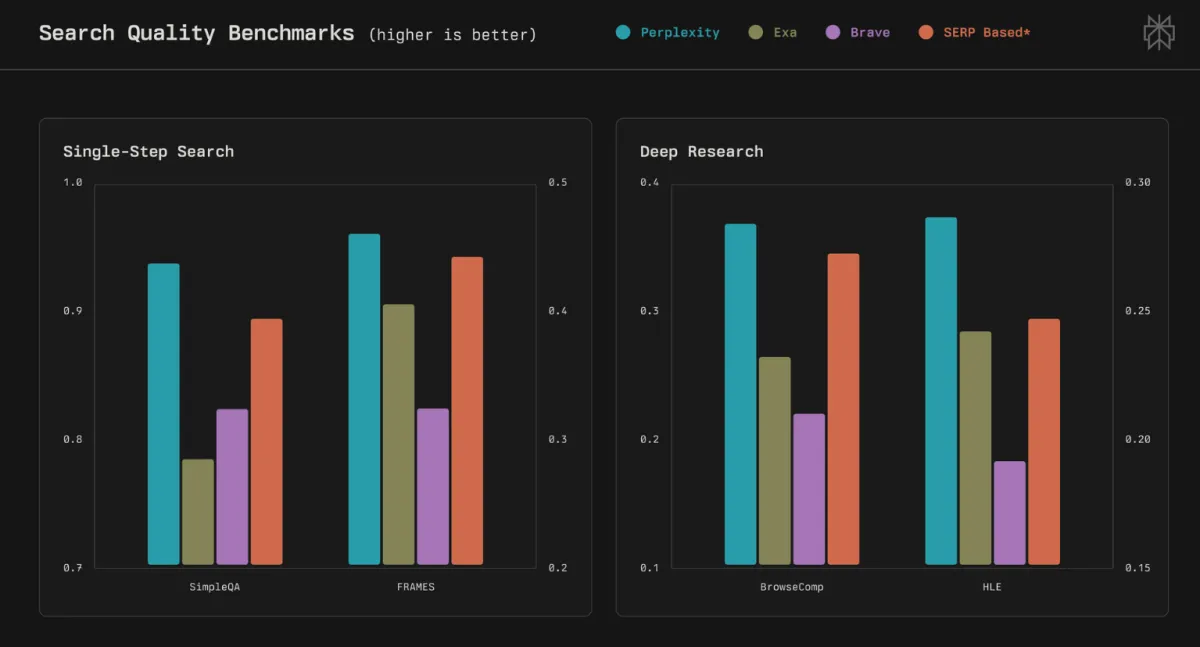
The company’s journey to building its own search stack began out of necessity. In a technical blog post accompanying the launch, Perplexity revealed that early versions of its product relied on existing commercial search APIs. However, they quickly hit a wall. These services were either prohibitively expensive, with one provider charging $200 per thousand queries, or simply not built for the unique demands of AI.