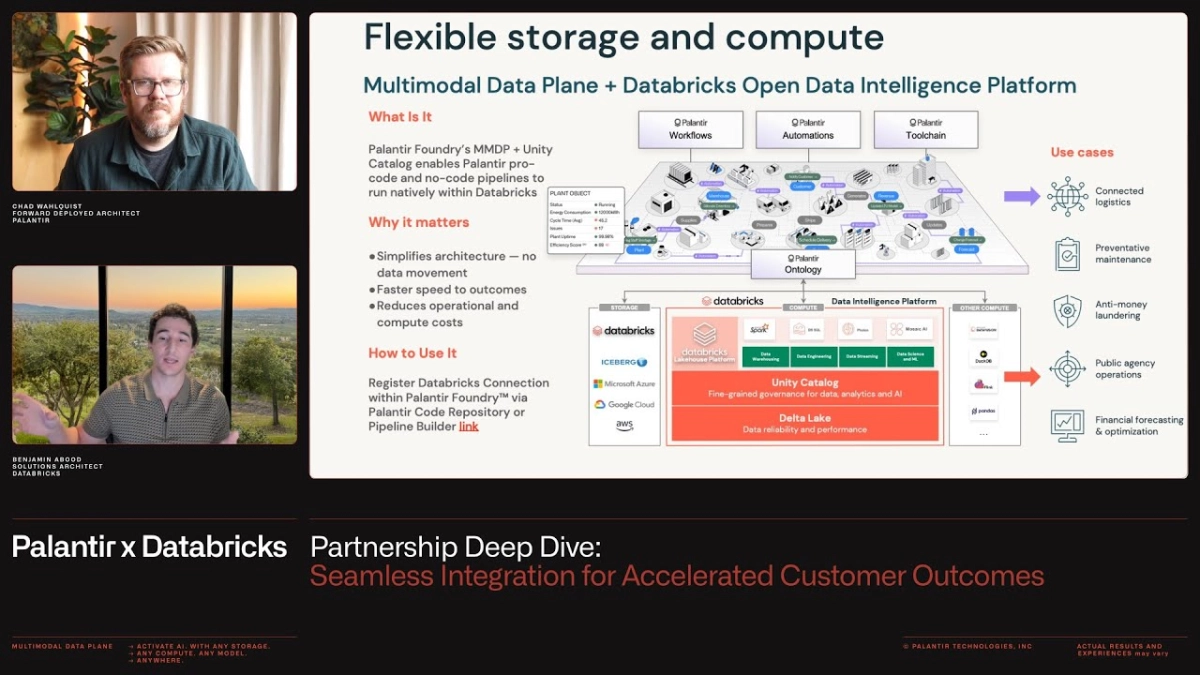
The future of operational artificial intelligence hinges not just on sophisticated models, but on eliminating the architectural friction that plagues most enterprise data stacks. This was the central theme of a recent deep dive presentation detailing the collaboration between Palantir and Databricks, demonstrating how two of the industry’s most powerful platforms are integrating at the foundational level to accelerate customer outcomes. The partnership is a direct response to a common reality: customers were already utilizing both Palantir Foundry and the Databricks Open Data Intelligence Platform side-by-side, but the lack of seamless interoperability created unnecessary complexity and latency.
Chad Walkowski, a Deployed Architect at Palantir, and Ben Abood, an Architect at Databricks, jointly presented the technical pillars of the newly deepened integration. They emphasized that the collaboration was inherently “customer-driven,” born from joint executive discussions last year centered on how to resolve the impedance mismatch between the two ecosystems. The integration focuses on four key pillars: Data Federation, Governance, Compute, and AI & Workflows, all designed to deliver value quicker by removing the necessity of moving and copying data across platforms.