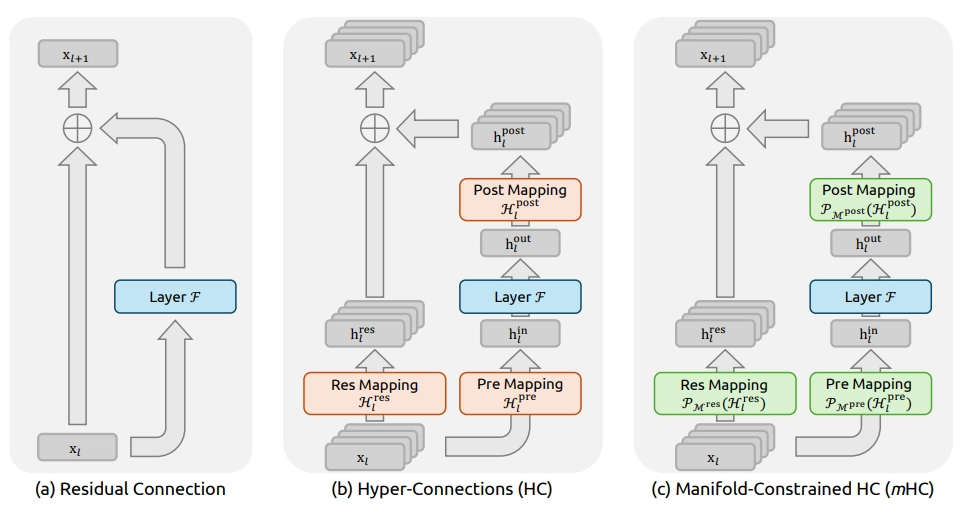
The relentless pursuit of wider, more complex neural networks just hit a significant milestone. Researchers at DeepSeek-AI have released a paper on Manifold-Constrained Hyper-Connections (mHC), a framework designed to upgrade the decade-old "residual connection" that powers nearly every modern AI model, from GPT-4 to Llama.
While standard residual connections act as a simple "highway" for data, mHC turns that highway into a multi-lane super-interchange, without the catastrophic crashes usually associated with such complexity.