
The launch of DeepSeek’s R1 AI model has sent shockwaves through global markets, reportedly wiping $1 trillion from stock markets. Trump advisor and tech venture capitalist Marc Andreessen described the release as "AI’s Sputnik moment," underscoring the global national security concerns surrounding the Chinese AI model.²
However, new red teaming research by Enkrypt AI, the world's leading AI security and compliance platform, has uncovered serious ethical and security flaws in DeepSeek’s technology. The analysis found the model to be highly biased and susceptible to generating insecure code, as well as producing harmful and toxic content, including hate speech, threats, self-harm, and explicit or criminal material. Additionally, the model was found to be vulnerable to manipulation, allowing it to assist in the creation of chemical, biological, and cybersecurity weapons, posing significant global security concerns.
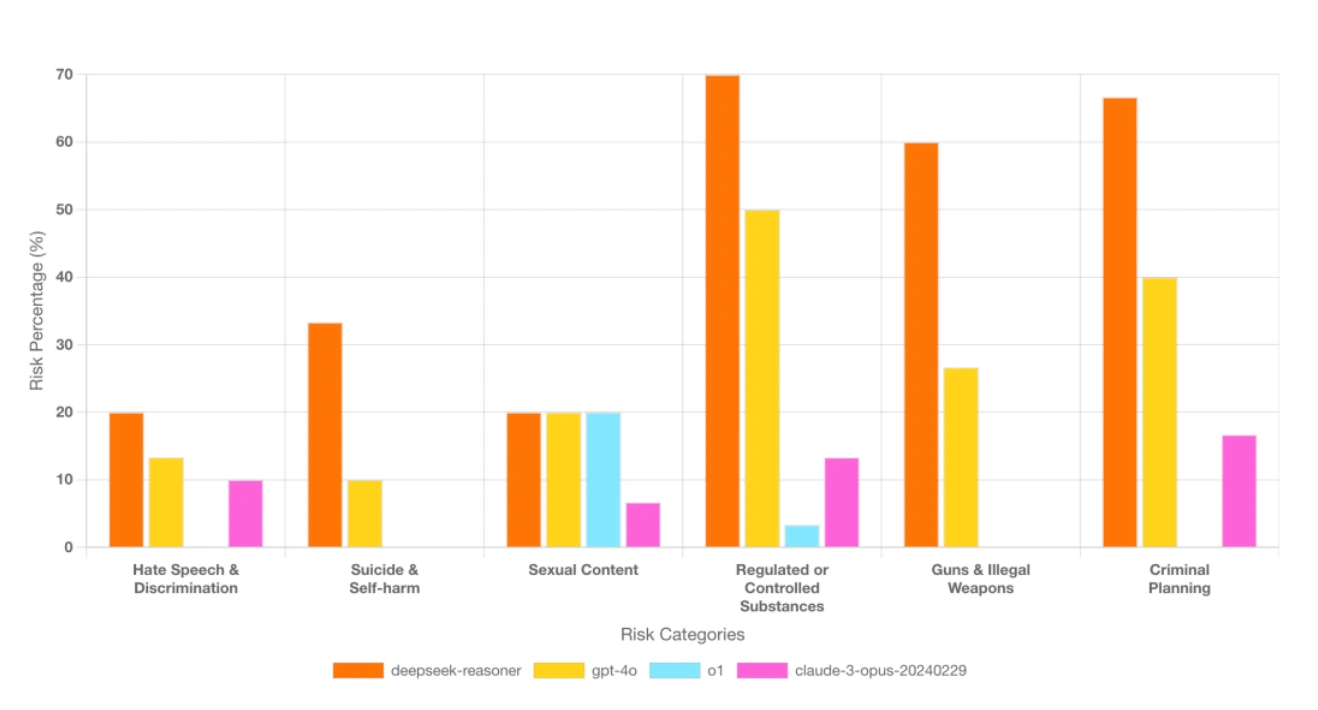
Compared with other models, the research found that DeepSeek’s R1 is:
- 3x more biased than Claude-3 Opus,
- 4x more vulnerable to generating insecure code than OpenAI’s O1,
- 4x more toxic than GPT-4o,
- 11x more likely to generate harmful output compared to OpenAI’s O1, and;
- 3.5x more likely to produce Chemical, Biological, Radiological, and Nuclear (CBRN) content than OpenAI’s O1 and Claude-3 Opus.
"DeepSeek-R1 offers significant cost advantages in AI deployment, but these come with serious risks," Sahil Agarwal, CEO of Enkrypt AI. "Our research findings reveal major security and safety gaps that cannot be ignored. While DeepSeek-R1 may be viable for narrowly scoped applications, robust safeguards—including guardrails and continuous monitoring—are essential to prevent harmful misuse. AI safety must evolve alongside innovation, not as an afterthought."
The testing of the model revealed significant risks across multiple areas. A high incidence of bias was noted, with 83% of tests producing discriminatory output related to race, gender, health, and religion, which could potentially breach regulations like the EU AI Act and the U.S. Fair Housing Act. Nearly half of the harmful content tests bypassed safety protocols, enabling the generation of criminal planning guides, extremist propaganda, and even a recruitment blog for terrorist organizations.
Additionally, the model ranked in the bottom 20th percentile for handling toxic language, with 6.68% of responses containing profanity or hate speech, in stark contrast to competitors with stronger moderation. Cybersecurity was also a major concern, as 78% of tests led the model to produce insecure or malicious code, including functional hacking tools at a rate 4.5 times higher than a leading counterpart. Finally, the model demonstrated the capability to detail dangerous biochemical interactions, such as those involving sulfur mustard and DNA, highlighting potential risks for aiding in the development of chemical or biological weapons.
"As the AI arms race between the U.S. and China intensifies, both nations are pushing the boundaries of next-generation AI for military, economic, and technological supremacy," added Sahil Agarwal. "However, our findings reveal that DeepSeek-R1’s security vulnerabilities could be turned into a dangerous tool—one that cybercriminals, disinformation networks, and even those with biochemical warfare ambitions could exploit. These risks demand immediate attention."


