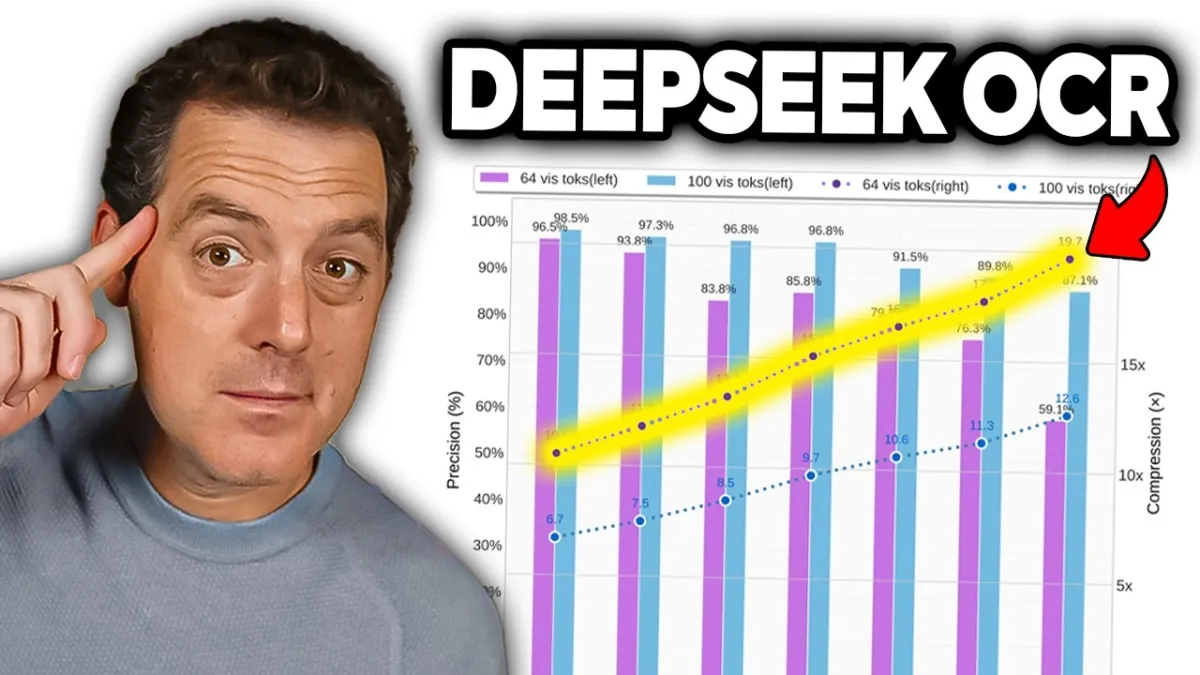
DeepSeek-AI has unveiled DeepSeek-OCR, a novel vision-language model (VLM) that promises to revolutionize how large language models (LLMs) process vast amounts of information. The core innovation lies in its ability to optically compress textual contexts, effectively expanding the effective "context window" for LLMs by up to tenfold. This breakthrough could dramatically enhance the efficiency and capability of AI systems, particularly for applications requiring the analysis of extensive documents.
Matthew Berman recently presented a deep dive into DeepSeek-AI’s latest innovation, DeepSeek-OCR, highlighting its potential to address a critical bottleneck in current LLM architectures. He explained how traditional text-based LLMs face significant computational challenges when processing long textual content, primarily due to the quadratic scaling of compute costs with sequence length. This limitation, often referred to as the context window problem, restricts the amount of information an LLM can consider at any given time to produce an optimal output.