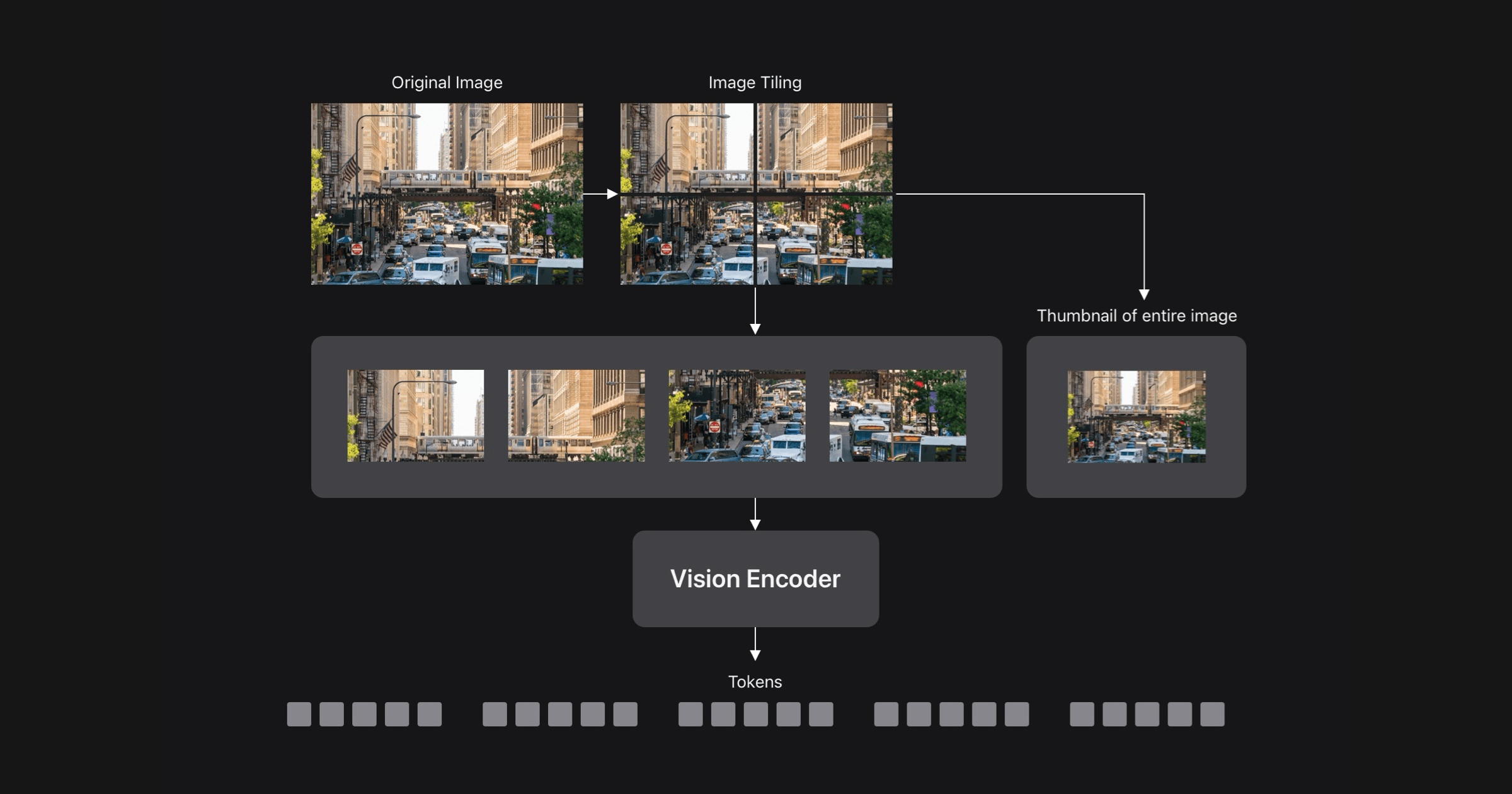
Apple has quietly unveiled a new machine learning initiative, FastVLM, aimed at significantly improving the efficiency of vision language models (VLMs). In a new post on its Machine Learning Research blog, the company detailed its work on "Efficient Vision Encoding for Vision Language Models," signaling a strategic focus on optimizing how AI processes visual information. This move underscores Apple's ongoing commitment to advancing on-device AI capabilities, particularly in areas where visual understanding is paramount.
Vision language models represent a critical frontier in artificial intelligence, enabling systems to understand and generate content based on both visual inputs (like images or video) and textual prompts. These models are the backbone of features ranging from advanced image search and content moderation to sophisticated AI assistants that can describe what they "see." However, their power comes at a significant computational cost. Processing high-resolution visual data and integrating it with linguistic understanding is incredibly resource-intensive, often requiring powerful cloud-based servers.