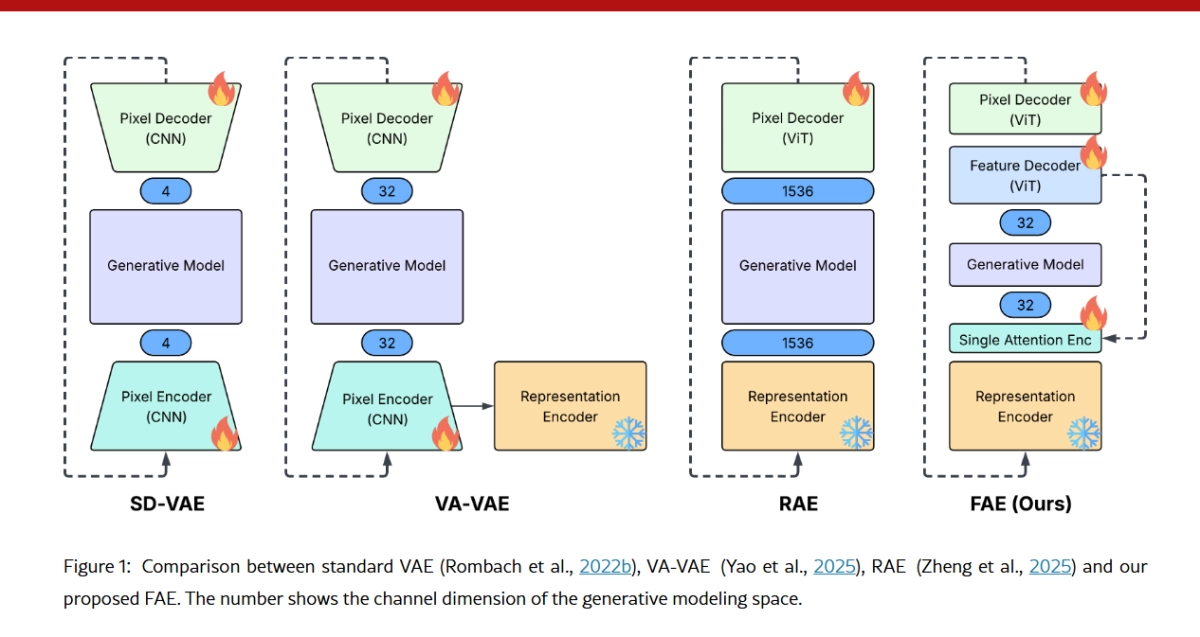
Generative AI is getting a major speed and efficiency boost, thanks to a surprisingly simple new framework from Apple researchers. The paper, "One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation," introduces the Feature Auto-Encoder (FAE), a novel approach that dramatically slashes the complexity required to integrate massive, pre-trained visual encoders (like DINOv2 or SigLIP) into cutting-edge generative models (like Diffusion Models and Normalizing Flows).
The key takeaway? Apple's FAE can take the high-dimensional, semantic-rich "language" of a large, self-supervised vision model and compress it into a tiny, generation-friendly latent space using little more than a single attention layer.