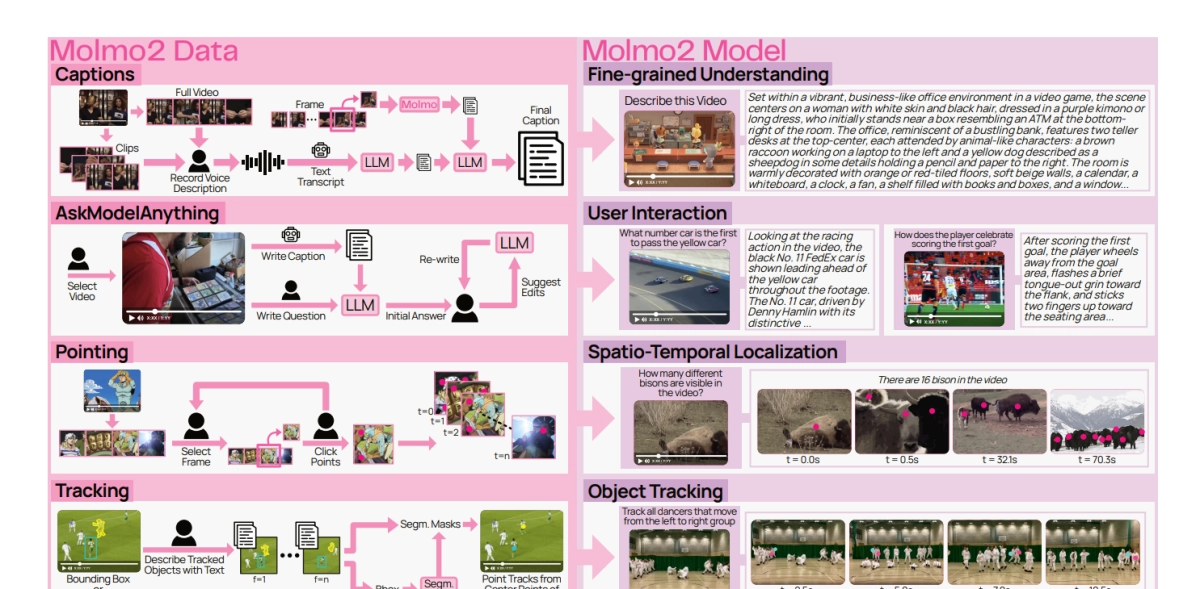
The Allen Institute for AI (AI2) has released Molmo2 VLM, a powerful new family of open-weight vision-language models that directly challenge proprietary systems like Gemini 3 Pro by mastering precise video grounding and tracking.
The strongest video-language models (VLMs) have long been locked behind corporate walls. While Google, OpenAI, and Anthropic battle over closed weights and proprietary data, the open-source community has struggled to build competitive foundations, often relying on synthetic data distilled from those very closed systems.