Frontier AI models have become excellent at generating boilerplate functions, but a new, rigorous test of their debugging capabilities suggests they are nowhere near ready to handle production outages.
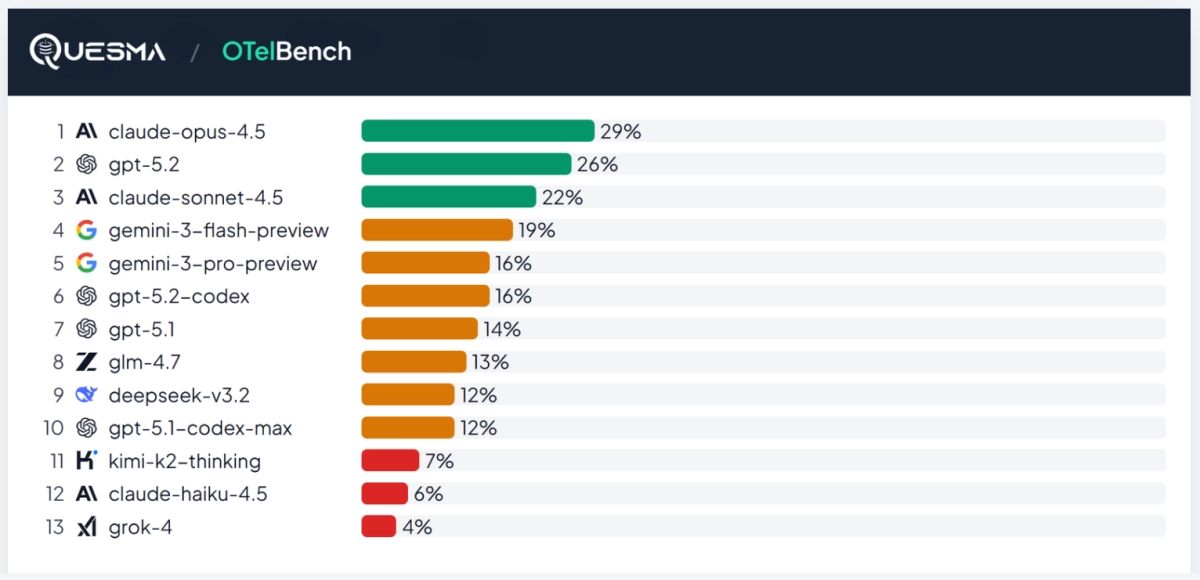
A benchmark released today, OTelBench, tested 14 leading large language models on their ability to perform a fundamental Site Reliability Engineering (SRE) task: adding distributed tracing to microservices using the industry standard, OpenTelemetry (OTel). The results are a stark reality check for the AI SRE hype cycle.