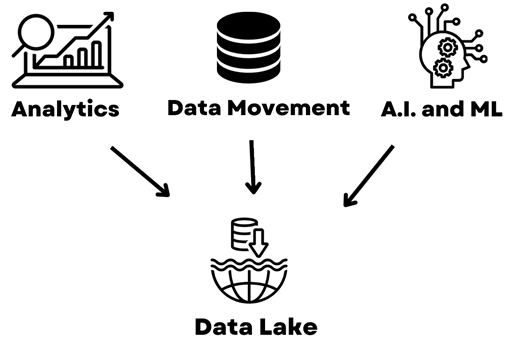
Data is king in today’s world, as companies need data to gain insights and an advantage over their competitors. A common challenge with data is that there is simply too much of it, and companies do not know where to start. Data can be spread across various disconnected systems and technologies, from databases to spreadsheets to file systems, etc. Additionally, all of the formats can be quite different also (structured and unstructured), which is another challenge!
To have any hope of getting this data together and analyzing it, a centralized solution is required, and this is where the concept of a Data Lake comes in.