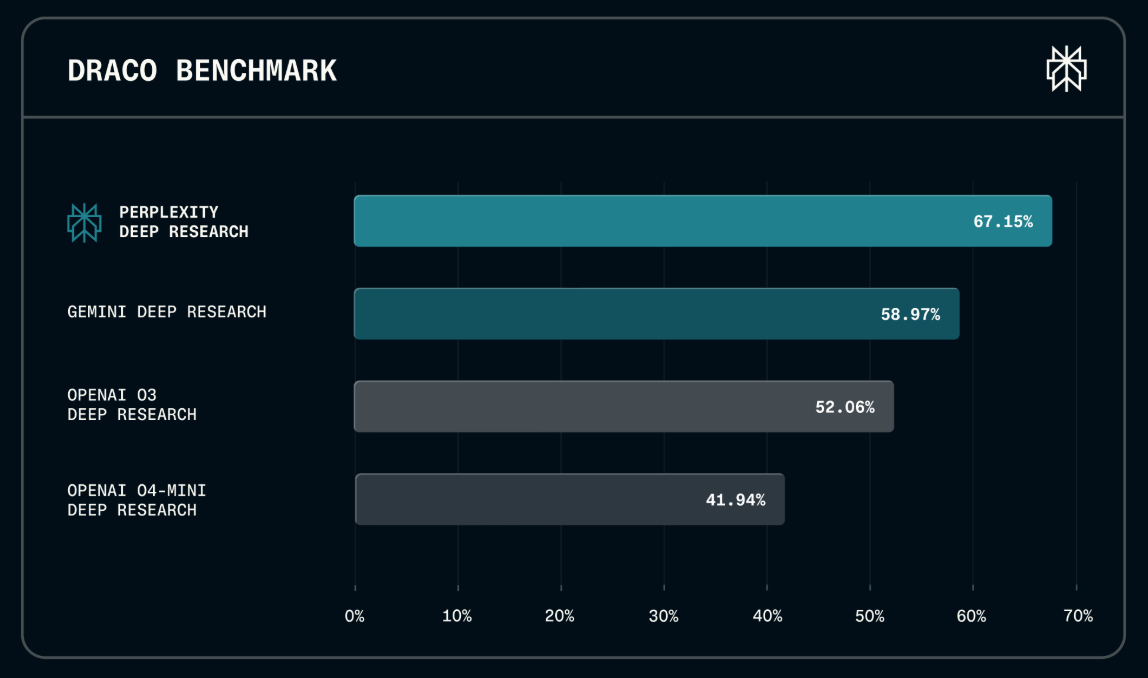
Perplexity AI today launched the Deep Research Accuracy, Completeness, and Objectivity (DRACO) Benchmark, an open-source tool designed to evaluate AI agents based on how users actually conduct complex research. The move aims to bridge the gap between AI models excelling at synthetic tasks and those capable of serving authentic user needs.
DRACO is model-agnostic, meaning it can be rerun as more powerful AI agents emerge, with Perplexity committing to publishing updated results. This also allows users to see performance gains directly reflected in products like Perplexity.ai's Deep Research feature.
