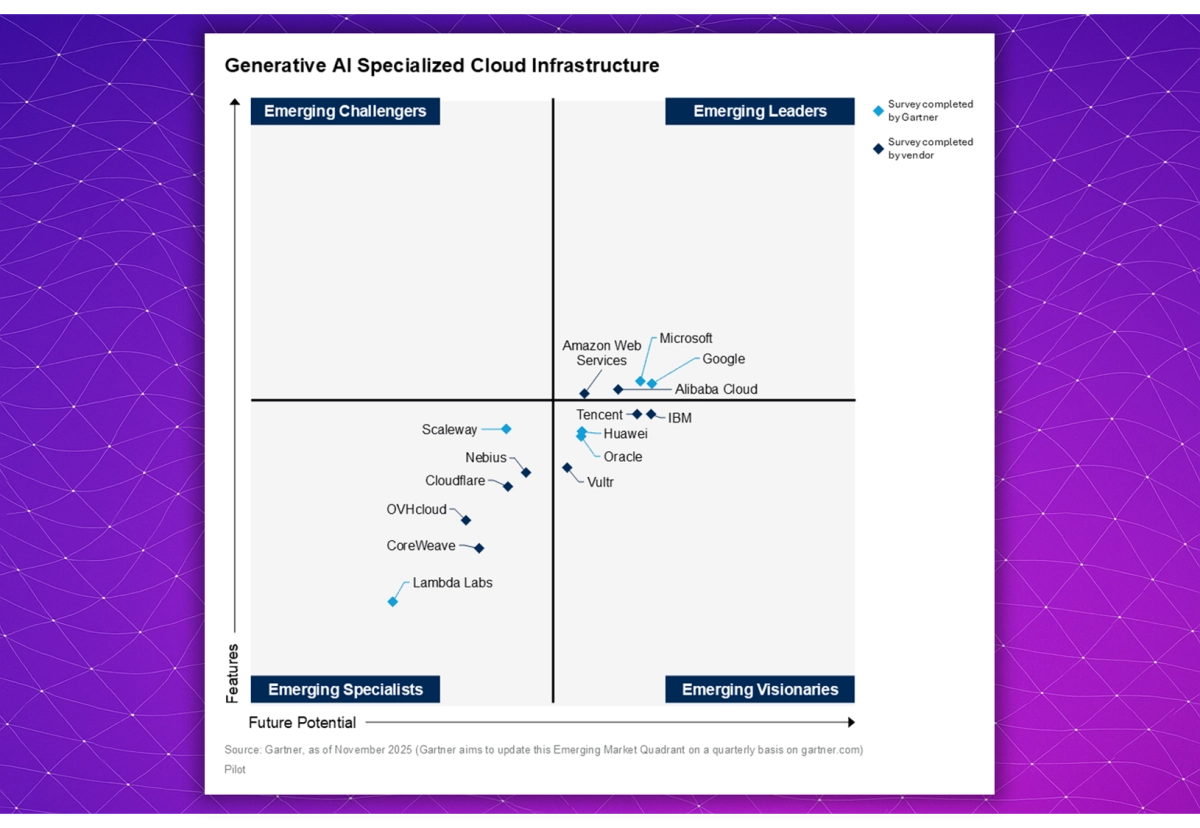
Gartner’s latest Emerging Market Quadrant (eMQ) for Generative AI Specialized Cloud Infrastructure arrives at a pivotal moment, as enterprises shift from early-stage model experimentation to globally distributed deployment strategies. The result is a rapidly reshaping ecosystem that no longer resembles the cloud market of the past decade.
In the 2025 edition, the Emerging Leaders quadrant is unsurprisingly dominated by the four hyperscalers that have built the largest GPU and AI-optimized compute footprints: Microsoft, Google, AWS, and Alibaba Cloud. Their positioning reflects large-scale procurement pipelines for accelerators, mature orchestration stacks, global networking fabrics, and tightly integrated enterprise ecosystems that make them the default choice for many large organizations.