Visual TL;DR. Low-Resource Languages leads to WARDEN System. Wardaman Language leads to WARDEN System. WARDEN System leads to Decoupled Architecture. Decoupled Architecture leads to Phoneme Transfer. Decoupled Architecture leads to LLM-Guided Dictionaries. Phoneme Transfer leads to Digitize Wardaman. LLM-Guided Dictionaries leads to Digitize Wardaman. Cross-Lingual Transfer leads to WARDEN System.
- Low-Resource Languages: AI models struggle with languages lacking extensive training data
- Wardaman Language: Endangered Australian indigenous language with only 6 hours audio
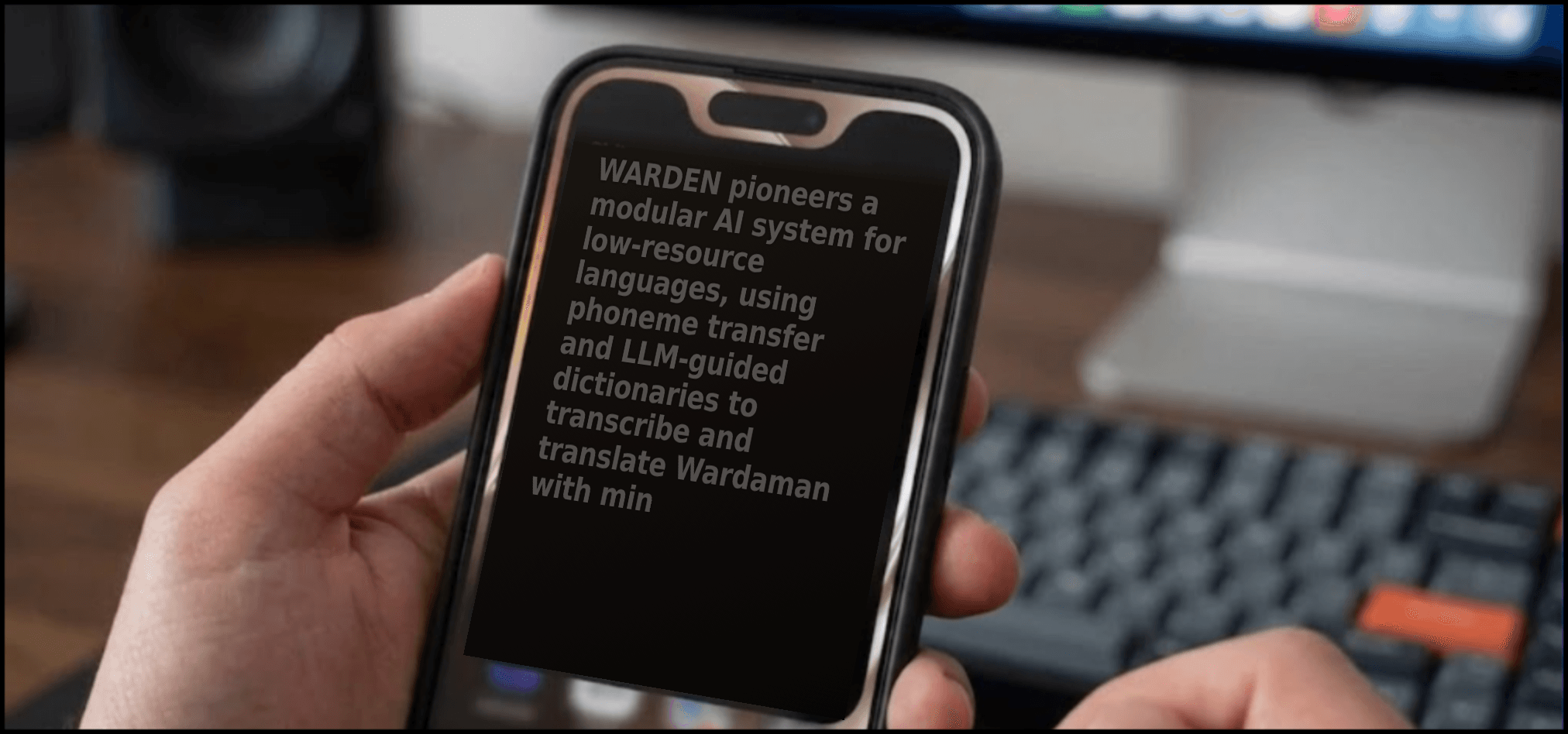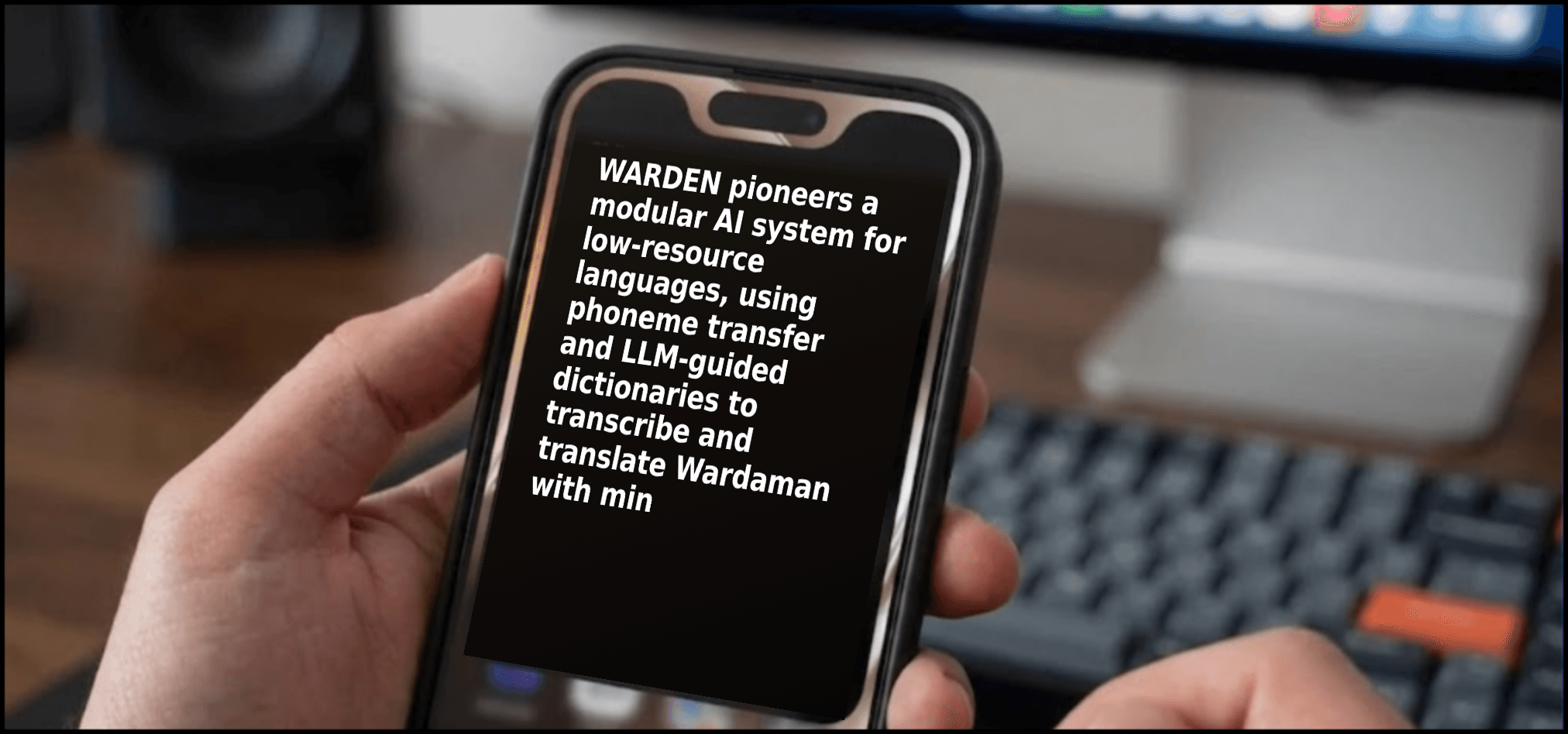
- WARDEN System: Modular AI for low-resource language transcription and translation
- Decoupled Architecture: Separates transcription and translation for specialized optimization
- Phoneme Transfer: Leverages sound patterns for transcription with minimal data
- LLM-Guided Dictionaries: Assists in creating translation resources for the language
- Cross-Lingual Transfer: Applies knowledge from high-resource languages to low-resource ones
- Digitize Wardaman: Enables processing and preservation of endangered languages
Visual TL;DR