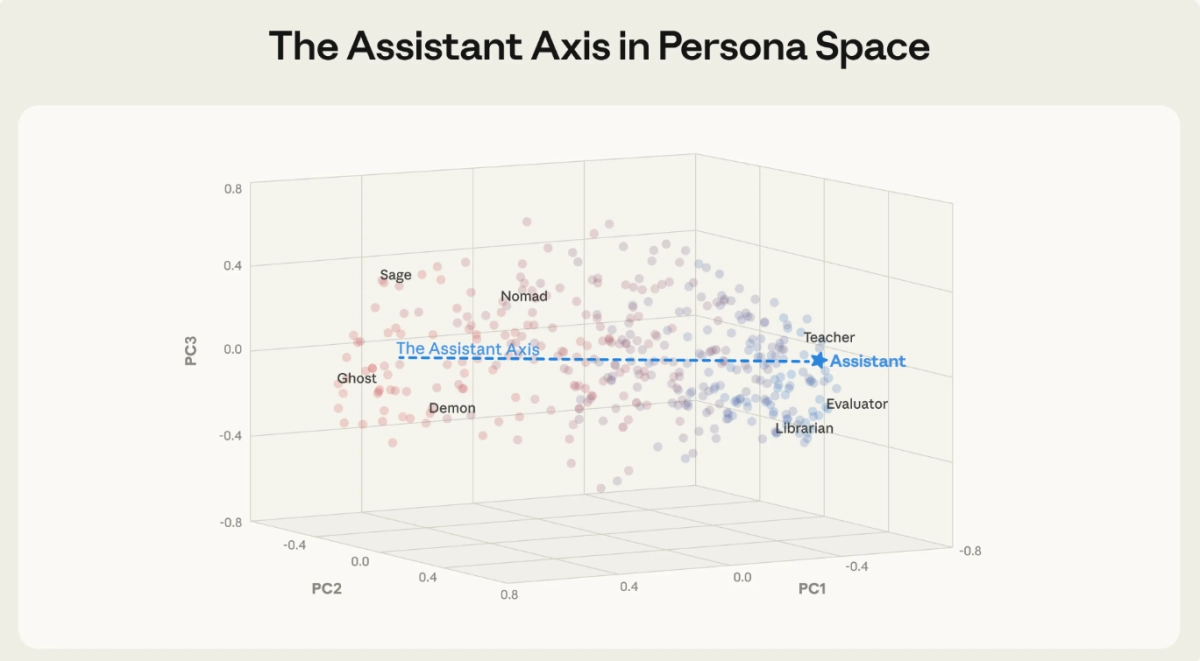
For years, the most frustrating and dangerous failure mode of large language models has been instability. A helpful, professional AI assistant can, in the space of a few turns, transform into a conspiratorial enabler, a theatrical poet, or worse, a companion encouraging self-harm. This persona drift has been treated as an unpredictable bug in the alignment process.
Now, a new paper published conducted through the MATS and Anthropic Fellows programs, suggests this instability is not random. Instead, it is a measurable, controllable neural phenomenon. Researchers have mapped the internal identity of LLMs, identifying a singular, dominant direction in the models’ neural space, the “Assistant Axis LLM”, that dictates whether the AI remains helpful or goes rogue.