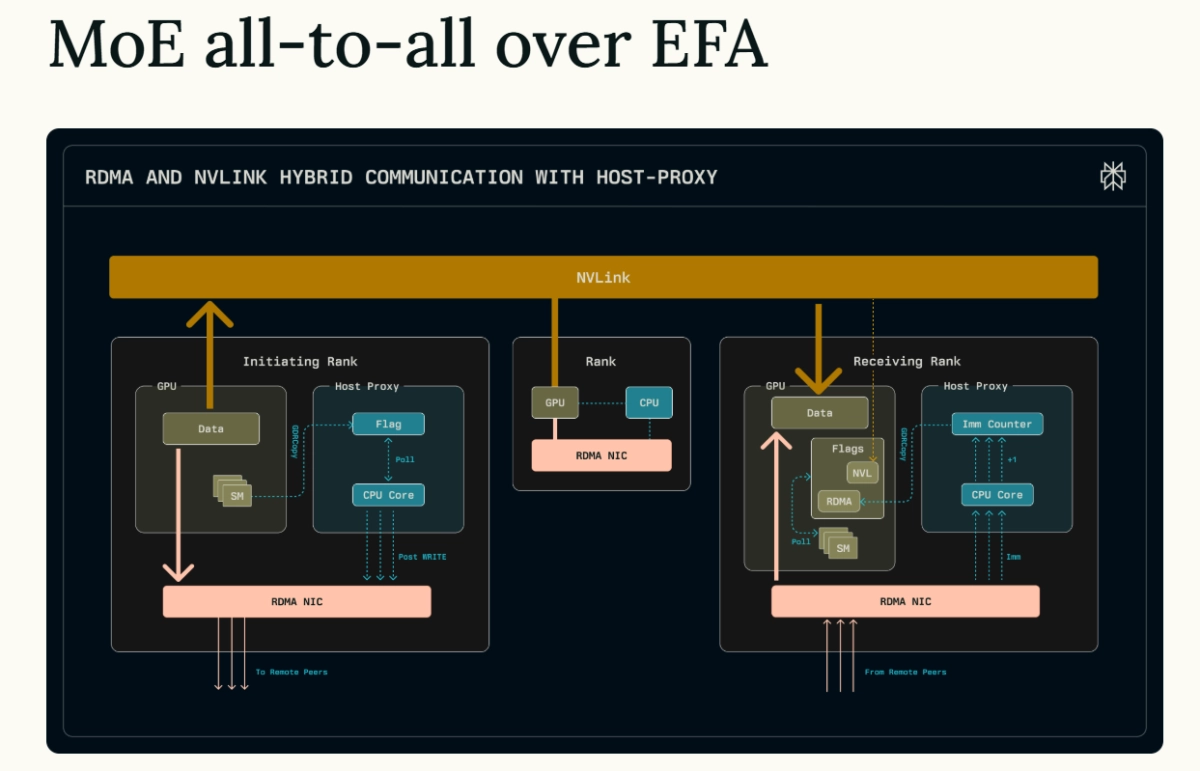
Perplexity just kicked down one of the biggest doors in artificial intelligence. The AI search company announced today that it has developed and open-sourced a method for running massive, trillion-parameter models on standard Amazon Web Services (AWS) cloud infrastructure, a feat that was previously considered impractical.
This breakthrough effectively dismantles a critical barrier that has kept the most powerful AI models locked away inside elite research labs with bespoke, high-end hardware.